That path to Ai: #4 ANN and Activation functions


Artificial neural networks
Artificial neural networks are one of the trending topics in nowadays, Applications based on this type of technology imitate the sophisticated functionality of the human brain, where neurons process information in parallel. Researchers have successfully proved the concept by creating prototypes and successful models, for example, pattern recognition and language translation. However, it is still a big challenge to have consciousness in these models. Maybe someday we will have enough science to understand conscious and test the capabilities of this science.
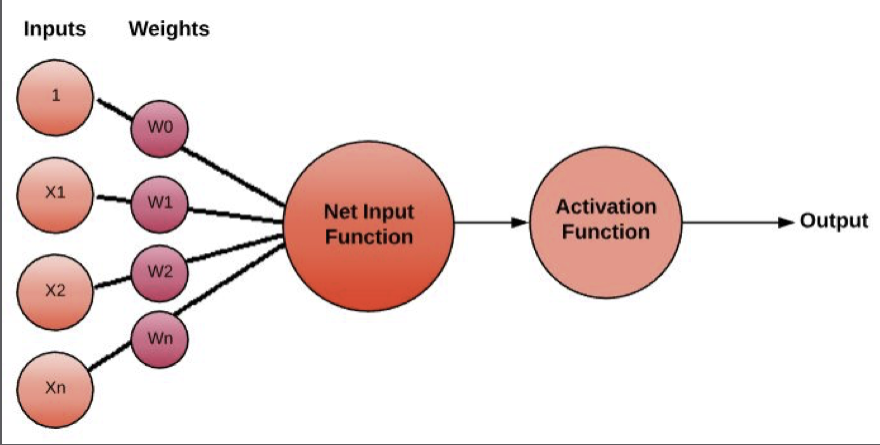
Artificial neural networks contain input. This input represents a layer of neurons (or units, nodes); those neurons are connected to the hidden layer of neurons and then connected to the output.
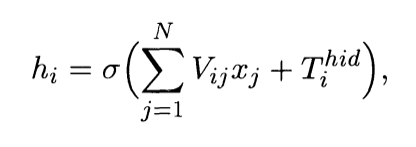
In Figure 6, it shows the architecture where lines connecting neurons are additionally appeared (Figure 07). Every association is related to a numeric number called weight. The output, hi, of neuron in the concealed layer is, where O () is called activation (or transfer) function, N represents the number of information neurons, Vij is the weights, xj contributions to the information neurons, and Tihid the edge terms of the hidden neurons. The motivation behind the activation function is, other than bringing nonlinearity into the neural network, to bound the estimation of the neuron, so the neural network is not deadened by divergent neurons
Activation functions
Activation functions are numerical equations that decide the output of a neural network. The process connects to every neuron in the network. It determines whether it should be activated or not, based on whether every neuron's input applies to the model's prediction. Activation functions also help normalise the output of every neuron. To a range somewhere in the field of 1 and 0 or between - 1 and 1. Activation functions must be computationally proficient because they calculate across thousands or even a massive number of neurons for every data test. Modern neural networks utilise a strategy called backpropagation (Backpropagation, is a method to consistently change the weights to minimise the contrast between real output and the one planning to achieve). It is an essential step to train the model, which puts an expand computational strain on the activation function and its subsidiary function.
Step function
The step function is generally utilised in crude neural networks without hidden layer or broadly referred to name as single-layer perceptrons. This kind of structure can classify linearly separable issues, for example, AND gate OR gate. As it were, all classes (0 and 1) get separate by a solitary linear line.
Sigmoid function
Sigmoid Functions are utilised unreasonably in neural networks. What recognises the perceptron from the sigmoid neuron or logistic neuron is the nearness of the sigmoid function or the logistic function in the sigmoid neuron. On the one hand, the perceptron outputs discrete 0 or 1 value; a sigmoid neuron outputs a smoother or continuous range of values somewhere in the range of 0 and 1. It is essential in Neural Networks that the output changes gradually with input. Deep neural networks are what is in use directly and seeing how a small change in the inclination value or the weights related with the artificial neurons influences the general value of the output of the neuron is significant. A perceptron may have the outputs flipped abruptly with a small change in the input value, hence leaving the AI engineer baffled. To watch the little changes in the output to come at the right value of the input, we necessitate a function to be applied straightaway result of weights and inclination value, so generally, the output is smooth.
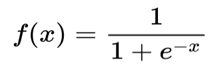
However, presently, the function could have been any function f () that is smooth like quadratic function, cubic function. The sigmoid function is all the time in use. Because of the exponential functions, and the way is similar to handle mathematically. Moreover, since learning algorithms include loads of separation, subsequently choosing a function that is computationally less expensive to deal with, is very acceptable.
Tanh function
Tanh or Tangent Hyperbolic function has qualities like sigmoid that we talked about above. It is nonlinear, so extraordinary we can stack layers. It will undoubtedly extend (- 1, 1). One highlight notice is that the gradient is better for tanh than sigmoid (derivatives are steeper). Choosing the sigmoid or tanh will rely upon the requirement of gradient strength. Like sigmoid, tanh likewise has a gradient issue.
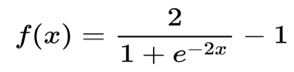
ReLu function
The rectified linear activation function or as known ReLu, it is a linear function that can return the input straightforwardly if it is positive, else, it will return zero. It became the standard choice as an activation function for some kinds of neural networks; because the model that utilises it is simpler to train and regularly accomplishes better performance.
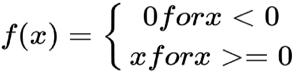
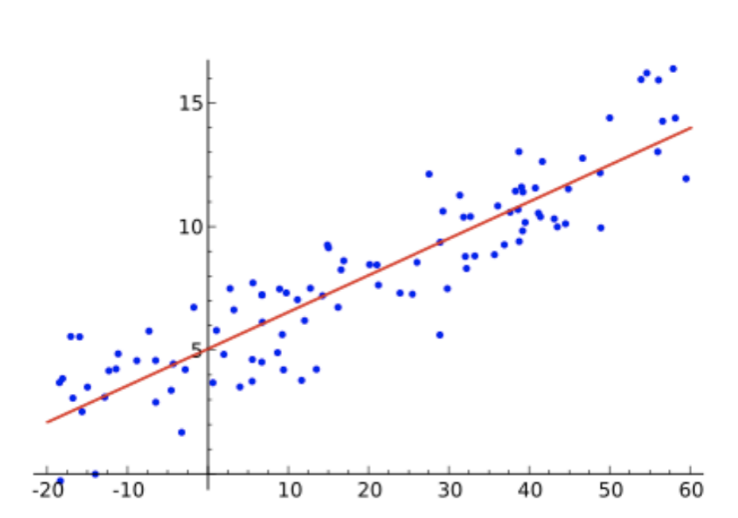
Linear regression
Linear regression is a statistical technique used frequently in different areas. It is powerful when it comes to an understanding of the relationship between the input/output. Linear regression is very handy when there are numerical values.
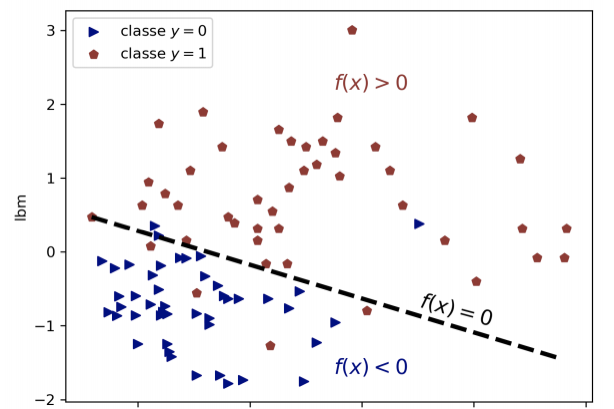
Logistic regression
Logistic regression is famous for its capabilities in classification; It works as a binary classification. This statistical and machine learning technique can model probabilities of some classes such as true/false 0/1 pass/fail.
Clustering
the way the author Aurélien Géron talked about clustering in his book is just fantastic (Hands-On Machine Learning with Scikit Learn, Keras and TensorFlow.), he described clustering as an enjoyable hike in the mountains, you discover a plant you have never observed. You glance around, and you notice a couple of something else. They are not indistinguishable, yet they are adequately comparative for you to realise that they in all likelihood have a place with similar plant varieties (or possibly identical class). You may require a botanist to mention to you what plant that is. However, you don't need to wait for a specialist to recognise gatherings of comparative looking items. This small story is what clustering is; the logic behind it is not something new for the human race. This Clustering method is used in machine learning to find similarities in a dataset; this type of algorithm is widely in use; for example, in recommendation systems, credit score calculation.