That path to Ai: #2 Supervised learning


It is a type of machine learning algorithms that learns from a provided input/output data to predict an un-provided output from the same form of input data in training. Supervised learning is often in our daily life, for example, the algorithm that indicates how much time a driver will take from point A to B, with the traffic and speed limit and all that stuff. Since just by processing useful historical data and know which information is correct from false, the data should be well processed and labelled. Then the algorithm can start comparing the input with the existing data. If the data is useful and well fitted with the module, the results can be very accurate. When it comes to supervised learning, three mathematical algorithms are the most used and popular.
·Bayesian classifiers
As reported by the Cambridge English Dictionary, "bias is the act of supporting or opposing a particular person or thing unfairly, allowing personal opinions to influence your judgment." Bayesian machine learning refers to having a prior belief and updating it later by using data. Mathematically, based on the Bayes formula:
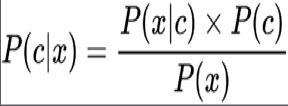
This mathematical formula is useful to calculate complicated predictions, one of the simple examples the author Chiheb used in page 9 Chapter 1. tossing a coin and trying to predict the output if it will be heads or tails is possible with this mathematical formula.
·Support vector machines
This supervised machine learning model sorts data into two categories. It is trained with a progression of data already classified into two categories, building the model and training. The task of an SVM algorithm is to figure out which type another data point has a place in. It makes SVM a sort of non-binary linear classifier.
An SVM algorithm ought to place objects into categories, yet have the margins between them on a graph as complete as conceivable.
few applications of SVM include:
- Text and hypertext classification
- Image classification
- Perceiving handwritten characters
- Biological sciences, including protein classification
·Decision trees
Decision trees are a unique machine learning algorithm, known for taking accurate decisions based on different results. Then it picks the closer decision to the correct provided data.
The way it represents the data is like an upside-down tree, all different paths connected to the root. (figure 02)
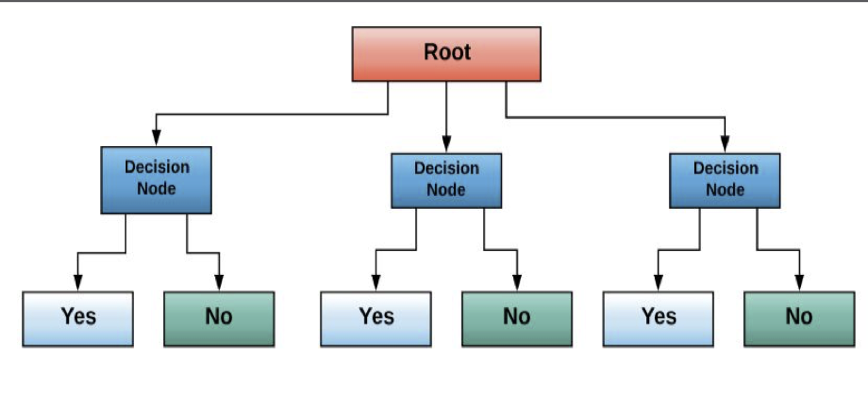
As we have in Figure 02, the algorithm uses ID3(Iterative Dichotomiser 3) it is an algorithm invented by Ross Quinlan, created to generate a decision tree from a specific dataset. It is now part of machine learning and natural language processing domains.



